
Data is one of the key components of any application. Clients/Users continually make data, throughout the day. Consistently, so much Data. In a short time an organization can gather a huge number of records, a huge number of users, and a few gigabytes of data stockpiling.
These Large Data Volumes can result in drowsy execution, including slower queries, search, and sandbox refreshing.
Salesforce provides customers to easily scale up their applications from small to large amounts of data. This scaling usually happens automatically, but as data sets get larger, the time complexity for particular operations grows. Operation times can be increased or decreased by several orders of magnitude. Basically it depends on the way in which architects design and configure data structures.
In this article we talk about best practices for handling large volumes of data in Salesforce.
-
The main processes affected by differing architectures and configurations are:
- Data extraction via reports and queries, or through list views
- Large number of records are loaded or updated, either using any tool like data loader, data import wizard or using integrations
- Choose the efficient operation for completing a task
- Industry based standards should be follow to accommodate schema changes or to do operations in database-enabled applications
- Sharing processes and bypassing the business rules
Techniques for Optimizing Performance with LDV
- Using Mashups
One way to deal with diminishing the measure of data in Salesforce is to keep up enormous data collections in an alternate application, and afterward make that application accessible to Salesforce varying. Salesforce alludes to such a plan as a mashup on the grounds that it gives a fast, inexactly coupled combination of the two applications. Mashups use Salesforce introduction to show Salesforce-hosted data and remotely hosted information. - Defer Sharing Calculation
In certain conditions, it may be proper to utilize a feature called defer sharing calculation, which permits clients to defer the preparation of sharing rules until after new clients, rules, and different content have been loaded. An association's head can utilize a defer sharing calculation permission to suspend and continue sharing estimations and to oversee two procedures: group member calculation and sharing rule calculation. - Using SOQL and SOSL
A SOQL query is the equal to a SELECT SQL statement, and a SOSL query is a programmatic way of performing a text-based search.
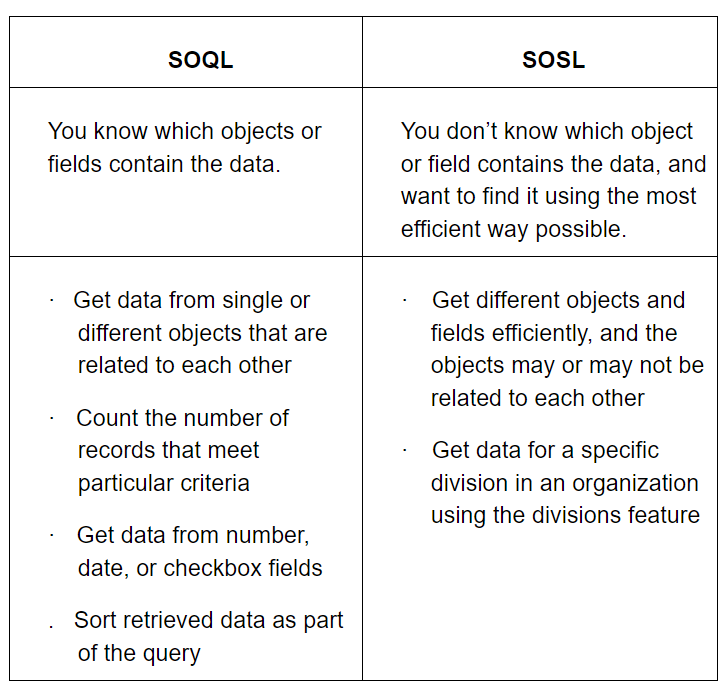
- Deleting Data
The deletion of Salesforce data can have a profound effect on the performance of large data volumes. Salesforce’s Recycle Bin stores the deleted data. It does not actually remove the data, it flags data as deleted and you can access it through the Recycle Bin. This process is known as soft deletion. While the data is soft deleted, it still affects database performance because the deleted records still reside in Salesforce org, and these have to be excluded while performing any queries.
Salesforce stores data in the Recycle Bin for 15 days, or until the Recycle Bin grows to a specific size. The data is deleted from the Recycle Bin after 15 days; or when the size limit is reached; or when the Recycle Bin is emptied using the UI, the API, or Apex.
Best Practices for Performance with LDV
-
Reporting
- Reduce the number of records when querying by using a value (condition) in the data.
- Reduce the number of joins by minimizing the number of: Objects and Relationships used in the report.
- Reduce the amount of data by retrieving only required fields in SOQL query, reports and list view.
-
Loading Data from the API
- Improving performance by using the Salesforce Bulk API when you have more than a few hundred thousand records.
- Reduce data to transfer and process: Update only those fields that have changed.
- Avoiding loading data into Salesforce by using mashups to create coupled integrations of applications.
-
Extracting Data from the API
- Use the most-efficient operations: When retrieving more than a million records, use the Bulk API query capabilities.
- Reduce the number of records to return: Be specific, use exact keywords and try to avoid wildcards to filter the data.
- Improving efficiency by using the setup area for searching to enable language optimizations, and turn on enhanced lookups and auto-complete for better performance on lookup fields.
-
SOQL and SOSL
- Allowing the indexed searches when SOQL queries with multiple WHERE filters cannot use indexes: Decompose the query and join their results.
- Using the most appropriate out of both, SOQL or SOSL, for a given scenario.
- Avoid timeouts on long SOQL queries: Optimize the SOQL query by using selective filters and limiting query scope.
-
Deleting Data
- Delete large volumes of data: When deleting large volumes of data, that involves more records approximately more than one million, use the hard delete option of the Bulk API. Because deleting such a large volume of data has more time complexity.
- Make the data deletion process more efficient: Always delete child records first when parent records have many childrens.
-
General
- Avoid sharing computations and make deployments more efficient: Any user should not own more than 10000 records.
- Improve performance: Use a data-tier strategy that disperse data over multiple objects, and get data on-demand from another object.
In this article we have discussed best practises on handling large volumes of data in Salesforce. By following best practices, Salesforce allows handling of large data without any significant degradation of performance.
For any query on LDV In Salesforce, contact support@astreait.com